Bitten by Sample Selection Bias
by eric
At this week’s meeting of the High Energy Astrophysics Division of the American Astronomical Society, I learned that one of the teams analyzing data from a NASA observatory had run into trouble with their machine learning classifier.Ā Their problem illustrates one of the particular challenges of machine learning in astronomy: sample selection bias.
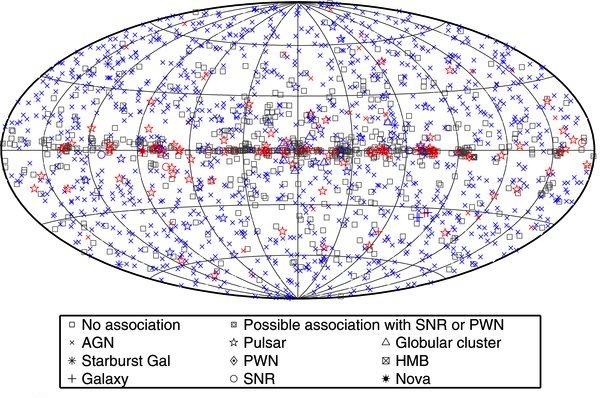
All-sky map of Fermi sources (Nolan et al. 2012).
At first glance, it looks like a classic machine learning problem.Ā The Fermi Gamma-Ray Space Telescope has performed a highly sensitive all-sky survey in high-energy gamma-rays and detected nearly two thousand sources, most of which are unidentified.Ā It’s expected that most of these will either be pulsars–rapidly-rotating neutron stars–or active galactic nuclei (AGN), accreting supermassive black holes in distant galaxies.Ā Many teams (including one I work with) are interested in detecting the Fermi pulsars in radio or optical bands.Ā We’re interested because many of these pulsars proving to be rare “black widow” systems, where the pulsar in the process of destroying its low-mass companion and it is possible to determine the mass of the neutron star.Ā However, telescope time is precious, so there needed to be a way to prioritize which systems to follow up first.
The pulsars and AGN are distinguished by their variability in the gamma-ray band and by the presence or absence of curvature in their spectra.Ā It seems obvious, then, to train a classifier on the data for the known systems and then use it to predict the class of the unknown systems, and several groups did just that.
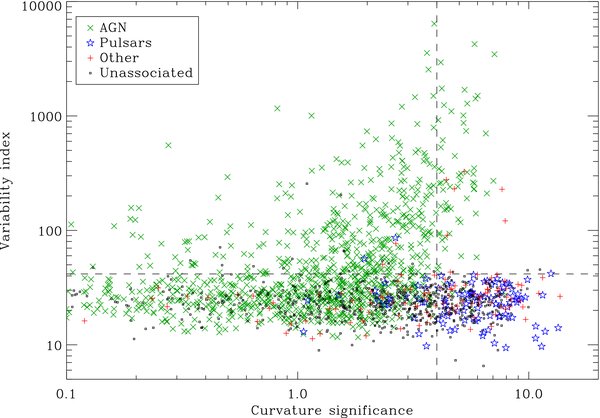
Spectral curvature vs variability for Fermi sources by source class (Nolan et al. 2012).
However, when the Pulsar Search Consortium searched the newly-prioritized list, they found fewer new pulsars, not more.Ā The problem turned out to be a bias in the training set: the known sources used for training are brighter than the unknown ones being predicted.Ā In this case, the major effect was that the fit of the spectral curvature was inconclusive for dim sources–there weren’t enough counts to tell a curved line from a straight one, so the features fed into the classifier weren’t reliable.Ā As usual, garbage in, garbage out.
In astronomy, this situation is quite frequent: the “labelled data” you’d like to use to train a classifier on is often systematically different from that which you’re trying to classify.Ā It may be brighter, nearer, or observed with a different instrument, but in any case blindly extrapolating to new regimes is unlikely to yield reliable results.Ā Joey Richards and his collaborators describe this problem of sample selection bias in great detail in their excellent paper, where they focus on the challenge of classifying different types of variable stars from their light curves.Ā They find that iterative Active Learning approaches are most effective at developing reliable classifiers when the unlabelled and labelled data may be drawn from different populations.Ā In Active Learning, the classifier identifies the unlabelled instances whose classification would most improve the performance of the classifier as a whole.Ā These targets can then be followed up in detail, classified, and the process repeated.
This approach worked well for variable star problem, where the features used in the classifier were valid for all the sources.Ā For the Fermi problem, the challenge is that one of the most informative parameters is unreliable for a subset of the sources.Ā In this case it might be more useful to develop additional features that might identify spectral characteristics even in the low-flux regime.